
In this blog post you will learn how stack overflow vulnerabilities are exploited and what happens under the hood. The next post on Return Oriented Programming (ROP) will teach you how memory corruption vulnerabilities can be exploited with ROP and introduce the XN exploit mitigation.
Stack buffer overflows are the canonical example of a memory corruption bug. They occur in programming languages like C and C++ where data arrays to be processed are allocated onto the stack without employing effective bounds checking on accesses to those arrays. In other words, a stack-based buffer overflow occurs when a function defines a data array as a local variable and fails to prevent excess data from being written to it, overflowing the array’s allocated limits. If the overflowing data corrupts nearby local variables and critical control-flow data, such as a return address saved onto the stack, an attacker can use this vulnerability to seize control of program flow.
The following simple program will serve as an example:
#include <stdio.h>
#include <string.h>
void func1(char *s)
{
char buffer[12];
strcpy(buffer, s);
}
int main(int argc, char *argv[])
{
if(argc > 1) {
func1(argv[1]);
printf("Everything is fine.\n");
}
}
This program contains a simple buffer overflow due to a missing bounds check for inputs greater than the allocated char buffer[12]. It prints “Everything is fine” when it receives an input string as an argument. But what happens if the input string is longer than the allocated buffer?
user@azeria-labs-arm:~$ ./program Hello Everything is fine. user@azeria-labs-arm:~$ ./program Helloooooo Everything is fine. user@azeria-labs-arm:~$ ./program Helloooooooooooooooo Segmentation fault
Aha! Segmentation fault. Let’s take a step back and look at what is happening under the hood. In my older blog post Functions and the Stack, I already covered how functions work on Arm32. In this post, I will focus on the exploitation aspect of function calls, which I briefly covered in my blog post Process Memory and Memory Corruptions.
When a subroutine is being called, the return address is being preserved in the Link Register. This is done with a Branch with Link (BL) or Branch with Link and Exchange (BLX) instruction. But what if this subroutine calls another function? The Link Register would be overwritten and the program would not find its way back to the previous function. The way this is handled is by preserving the return address on the stack with a PUSH instruction. The PUSH instruction stores the register it is given (in this case LR: push {LR}) to the top of the stack before overwriting the register LR with the new return address.
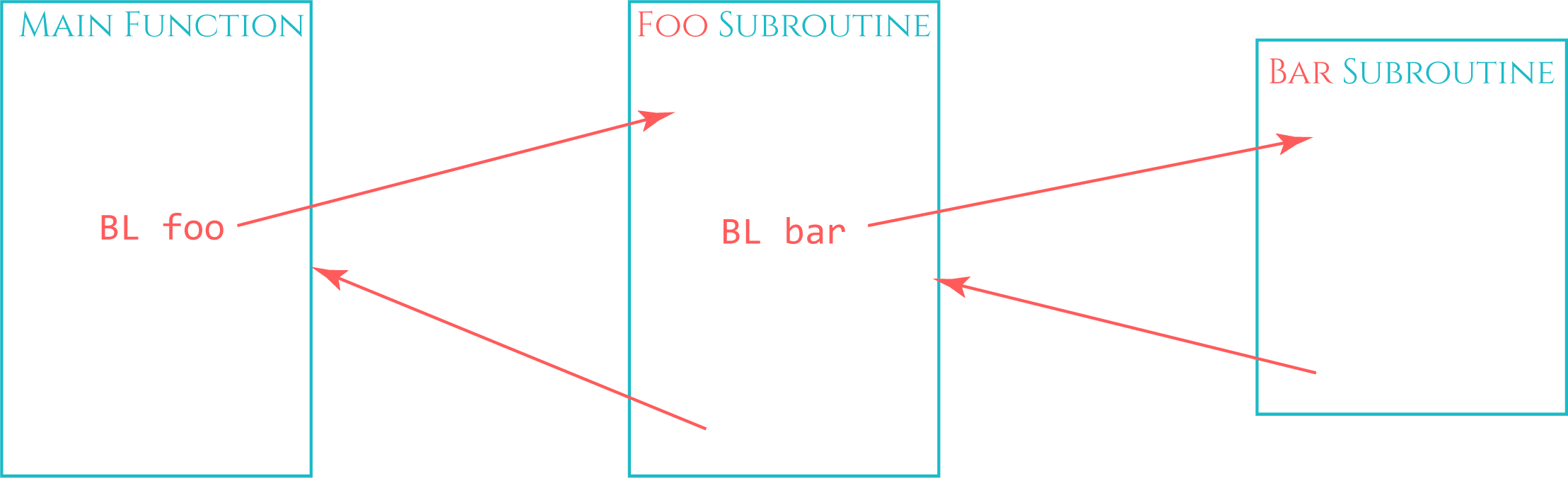
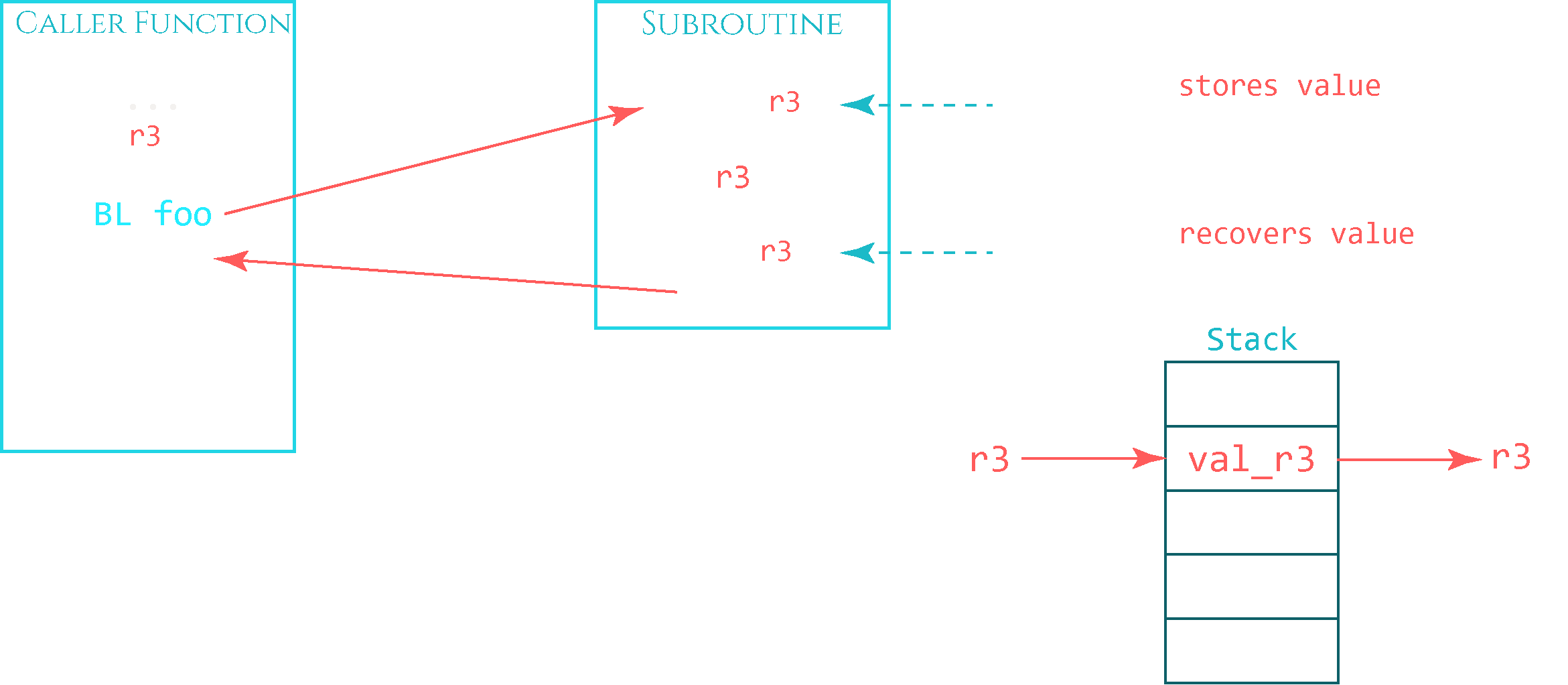
The same logic is used for registers that are being reused in a subroutine but need to keep track of the original value. In the next graphic you can see that the caller function uses register R3 as a counter, for example. The subroutine happens to require R3 for its own purposes and overwrites R3 with a different value and processes it in some way. To preserve the original value of R3, it gets pushed onto the stack at the beginning of the subroutine, changed and processed, and then restored to its original value by loading it from the top of the stack back to R3 with a POP instruction.
Let’s have a look at our stack overflow program. In func1, you can see that R7 and LR are being preserved on the stack because this function is about change the original value of R7 and call strcpy with a BLX instruction that overwrites LR with the new return address.
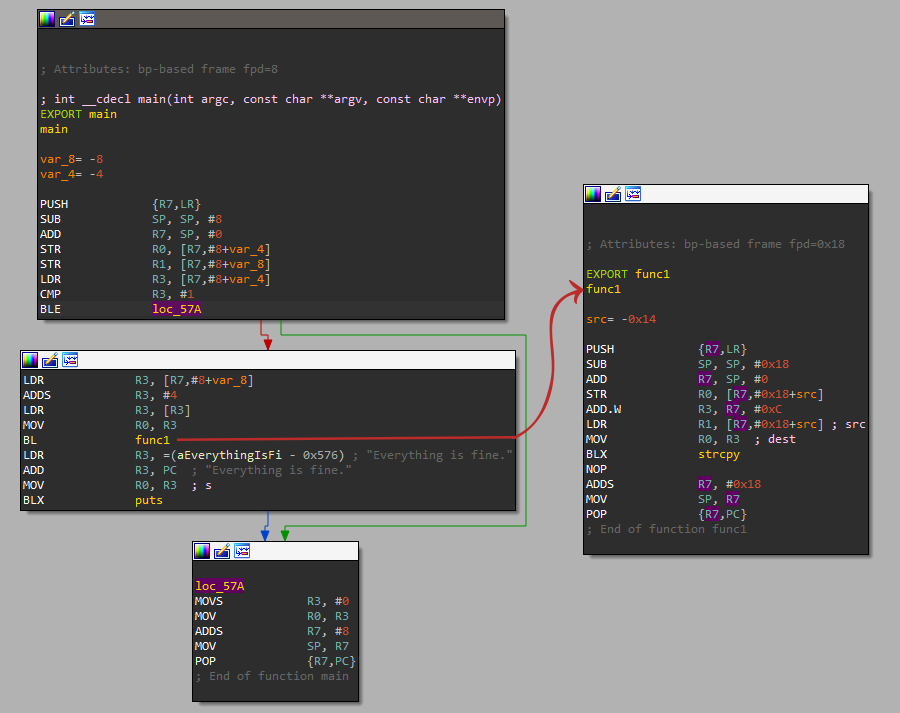
Can you already guess how this logic gives us the ability to take control over the program-flow? Func1 first saves the return address stored in LR onto the stack, but at the end of the function it stores this value from the stack back to PC. What is PC used for again? PC is the register that holds the address of the next instruction to be executed. Convenient, isn’t it?
Let’s look at this from the stack perspective. Every function gets its own stack frame where it can store the return address and local variables, temporary values, etc. This function is also responsible for cleaning up after itself. This means that the first value it pushes onto the stack is the last value it pops back where it belongs.
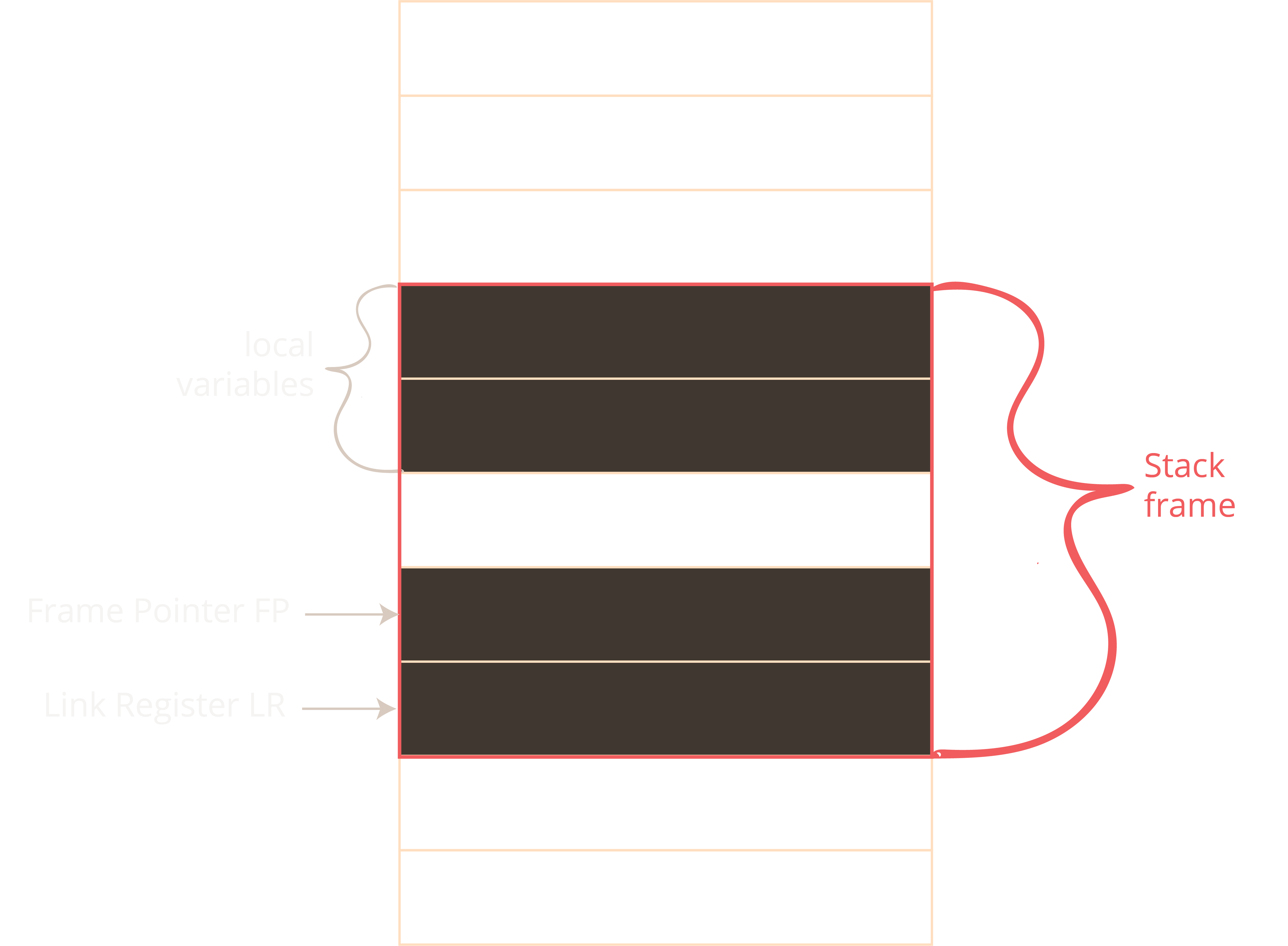
How can we exploit this? In this example, a function stores the return address onto the stack and defines a local variable that is defined as a sequence of characters. The buffer is allocated by “moving” the Stack Pointer (SP) up by the number of bytes the buffer requires. The write direction is “down” (if you think of the stack growing “up”).
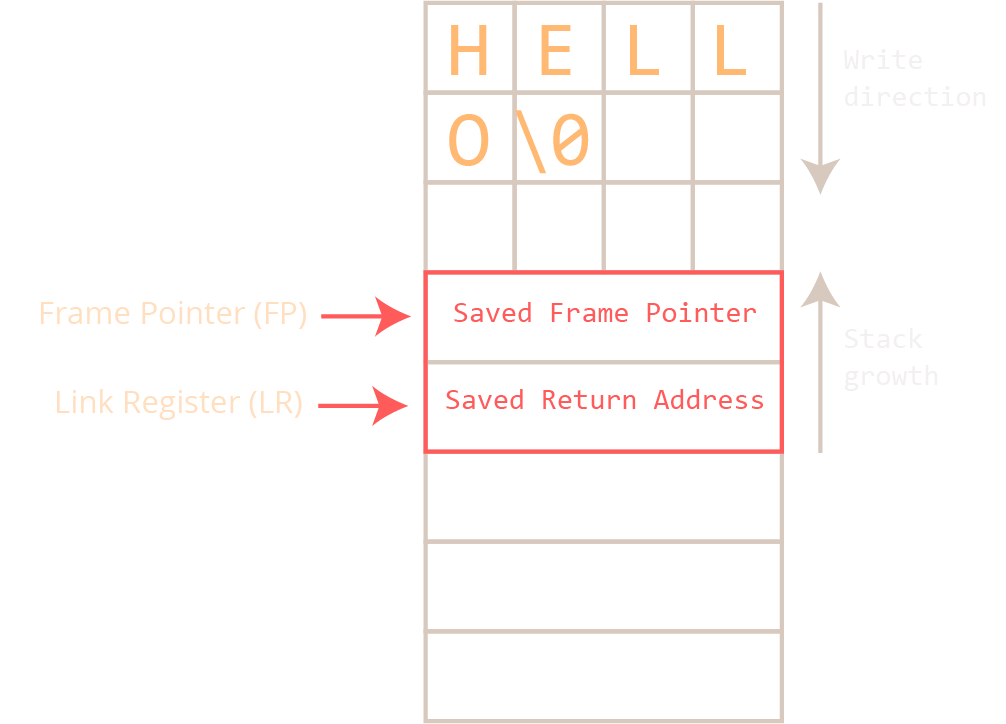
If the input string is “Hello”, it gets written into this allocated buffer and everything continues as expected. What if the input string is larger than the allocation can hold and there is no size check in place? You guessed it. If all elements of the buffer are filled, followed by characters that spill past the end of the buffer, the return address gets overwritten.
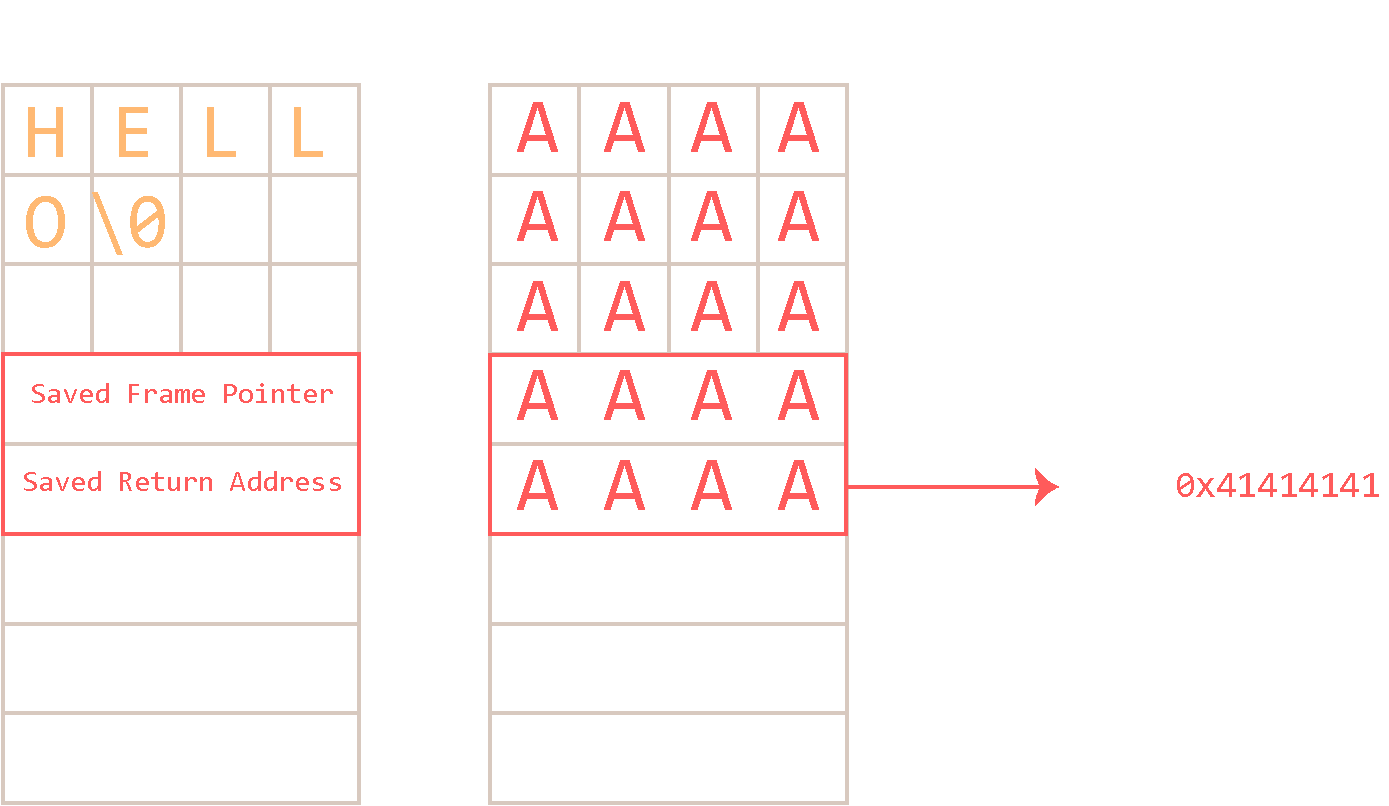
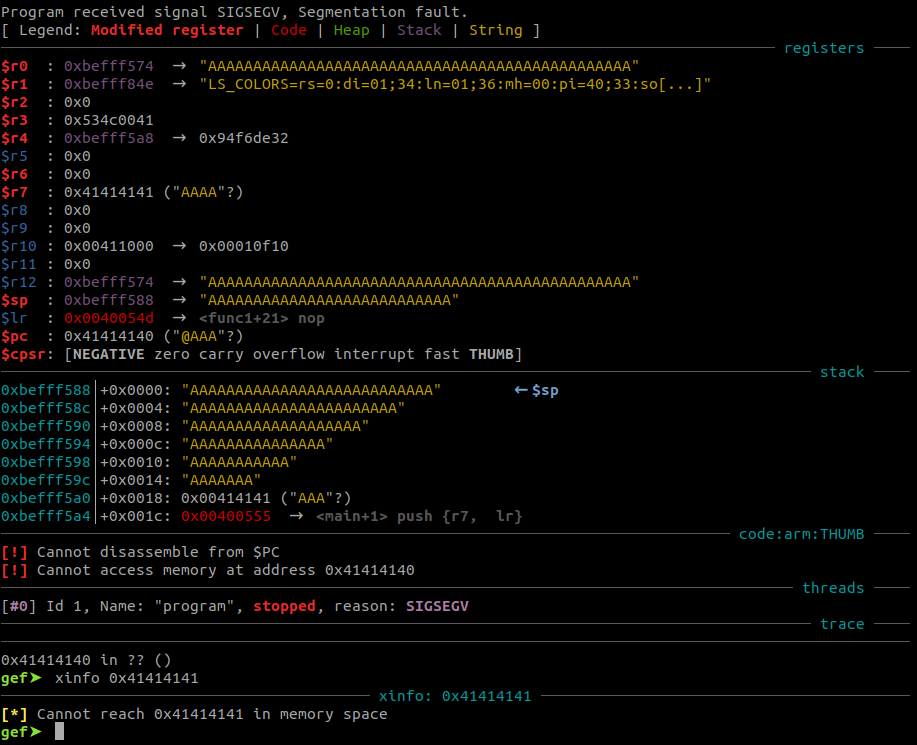
When the function ends and tries to restore program execution to its caller with the POP {PC} instruction, it will happily take whatever value at the position it expects the return address and store it in PC. In this case, program-flow is redirected to address 0x41414141 (AAAA). The program will try to execute the instruction at this address, but this address cannot be reached in memory space (as shown by executing xinfo 0x41414141 in GDB/GEF) and the program aborts with a SIGSEGV, Segmentation fault.
Continue with Return Oriented Programming (ROP) on Arm32.
