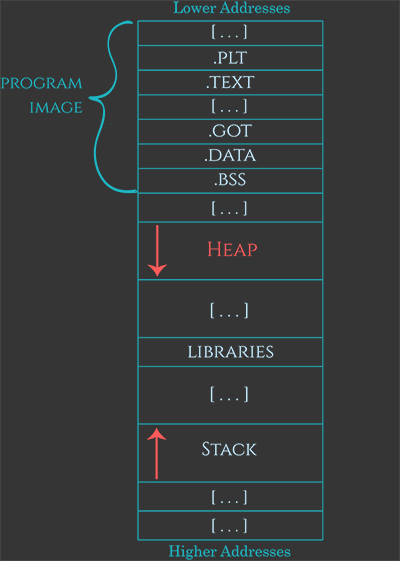
Buffer overflows are one of the most widespread memory corruption classes and are usually caused by a programming mistake which allows the user to supply more data than there is available for the destination variable (buffer). This happens, for example, when vulnerable functions, such as gets, strcpy, memcpy or others are used along with data supplied by the user. These functions do not check the length of the user’s data which can result into writing past (overflowing) the allocated buffer. To get a better understanding, we will look into basics of Stack and Heap based buffer overflows.
Stack Overflow
Stack overflow, as the name suggests, is a memory corruption affecting the Stack. While in most cases arbitrary corruption of the Stack would most likely result in a program’s crash, a carefully crafted Stack buffer overflow can lead to arbitrary code execution. The following picture shows an abstract overview of how the Stack can get corrupted.
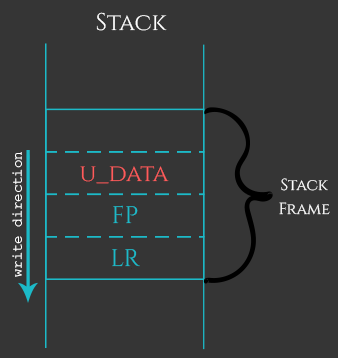
As you can see in the picture above, the Stack frame (a small part of the whole Stack dedicated for a specific function) can have various components: user data, previous Frame Pointer, previous Link Register, etc. In case the user provides too much of data for a controlled variable, the FP and LR fields might get overwritten. This breaks the execution of the program, because the user corrupts the address where the application will return/jump after the current function is finished.
To check how it looks like in practice we can use this example:
/*azeria@labs:~/exp $ gcc stack.c -o stack*/
#include "stdio.h"
int main(int argc, char **argv)
{
char buffer[8];
gets(buffer);
}
Our sample program uses the variable “buffer”, with the length of 8 characters, and a function “gets” for user’s input, which simply sets the value of the variable “buffer” to whatever input the user provides. The disassembled code of this program looks like the following:
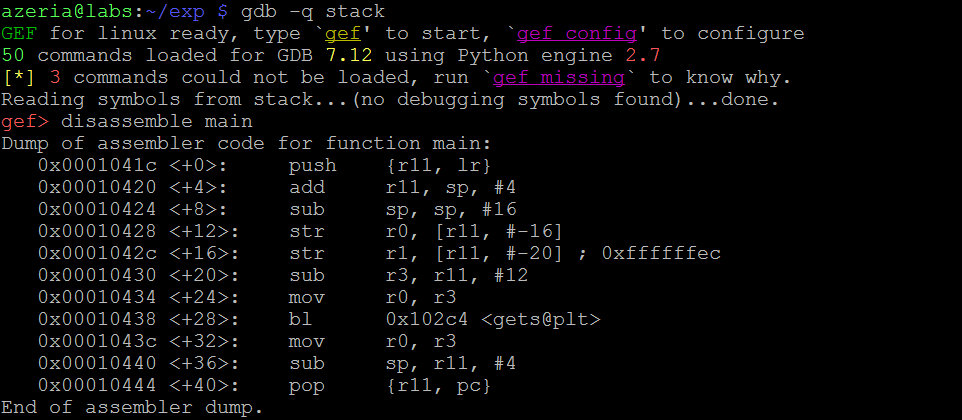
Here we suspect that a memory corruption could happen right after the function “gets” is completed. To investigate this, we place a break-point right after the branch instruction that calls the “gets” function – in our case, at address 0x0001043c. To reduce the noise we configure GEF’s layout to show us only the code and the Stack (see the command in the picture below). Once the break-point is set, we proceed with the program and provide 7 A’s as the user’s input (we use 7 A’s, because a null-byte will be automatically appended by function “gets”).
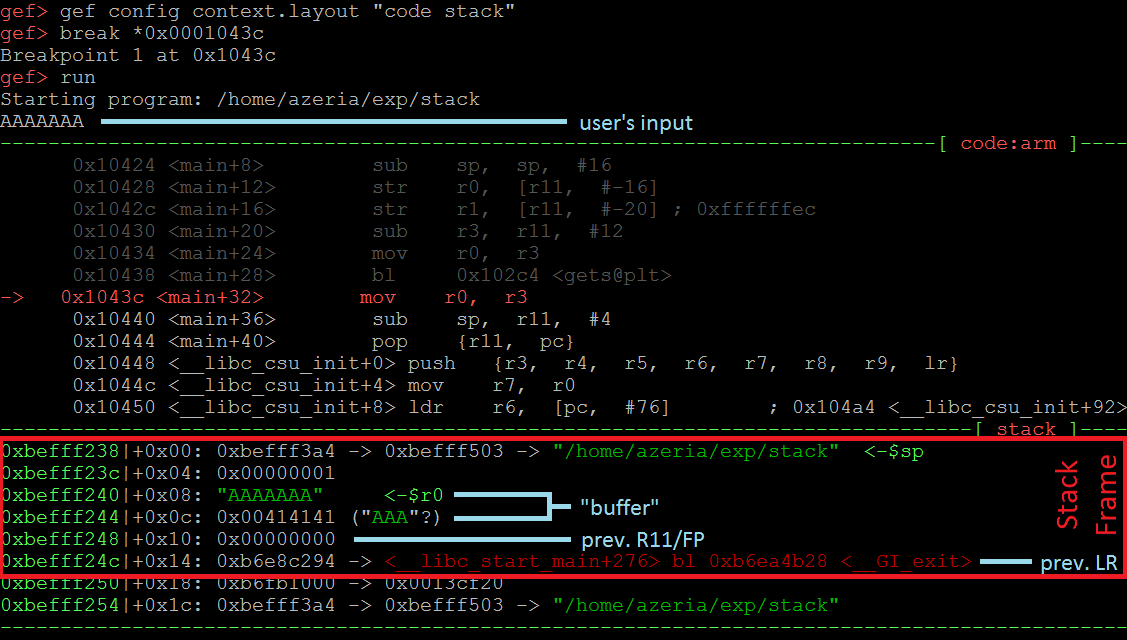
When we investigate the Stack of our example we see (image above) that the Stack frame is not corrupted. This is because the input supplied by the user fits in the expected 8 byte buffer and the previous FP and LR values within the Stack frame are not corrupted. Now let’s provide 16 A’s and see what happens.
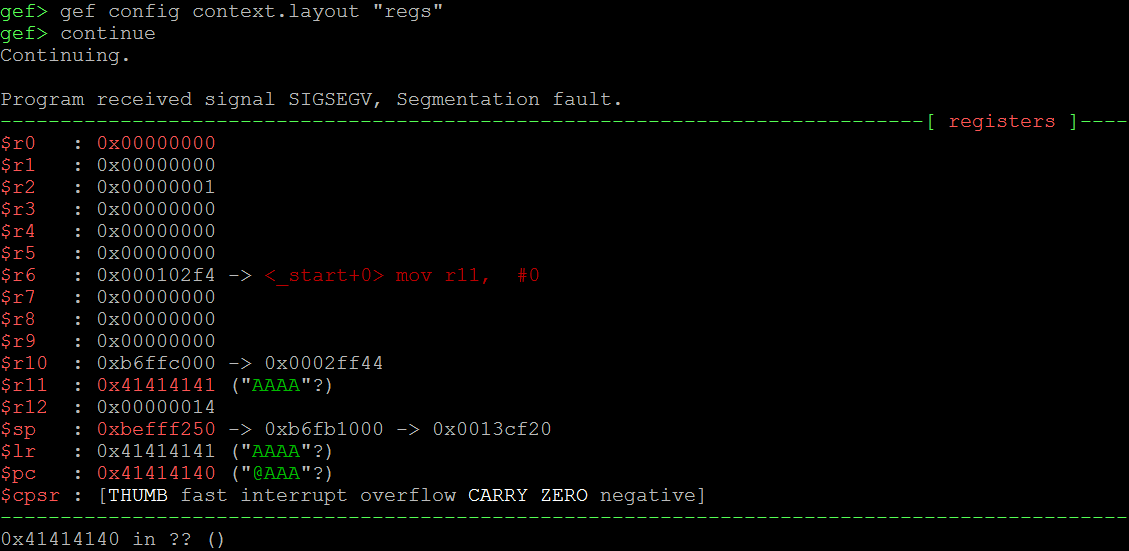
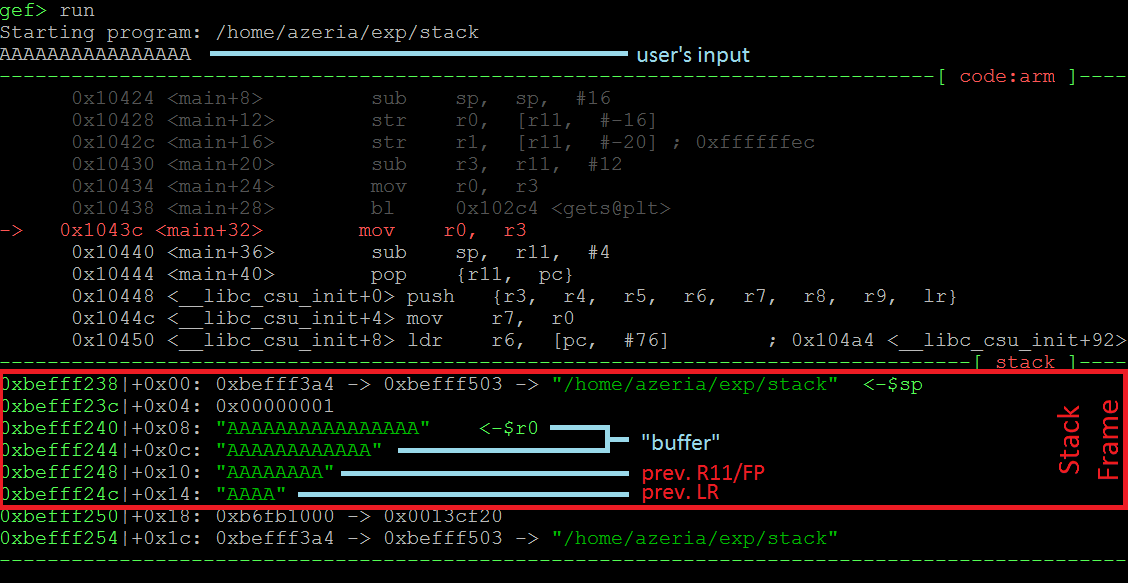 In the second example we see (image above) that when we provide too much of data for the function “gets”, it does not stop at the boundaries of the target buffer and keeps writing “down the Stack”. This causes our previous FP and LR values to be corrupted. When we continue running the program, the program crashes (causes a “Segmentation fault”), because during the epilogue of the current function the previous values of FP and LR are “poped” off the Stack into R11 and PC registers forcing the program to jump to address 0x41414140 (last byte gets automatically converted to 0x40 because of the switch to Thumb mode), which in this case is an illegal address. The picture below shows us the values of the registers (take a look at $pc) at the time of the crash.
In the second example we see (image above) that when we provide too much of data for the function “gets”, it does not stop at the boundaries of the target buffer and keeps writing “down the Stack”. This causes our previous FP and LR values to be corrupted. When we continue running the program, the program crashes (causes a “Segmentation fault”), because during the epilogue of the current function the previous values of FP and LR are “poped” off the Stack into R11 and PC registers forcing the program to jump to address 0x41414140 (last byte gets automatically converted to 0x40 because of the switch to Thumb mode), which in this case is an illegal address. The picture below shows us the values of the registers (take a look at $pc) at the time of the crash.
Heap Overflow
(If you want to learn how to heap works under the hood, read my post on “Understanding the GLibc Heap Implementation“)
First of all, Heap is a more complicated memory location, mainly because of the way it is managed. To keep things simple, we stick with the fact that every object placed in the Heap memory section is “packed” into a “chunk” having two parts: header and user data (which sometimes the user controls fully). In the Heap’s case, the memory corruption happens when the user is able to write more data than is expected. In that case, the corruption might happen within the chunk’s boundaries (intra-chunk Heap overflow), or across the boundaries of two (or more) chunks (inter-chunk Heap overflow). To put things in perspective, let’s take a look at the following illustration.
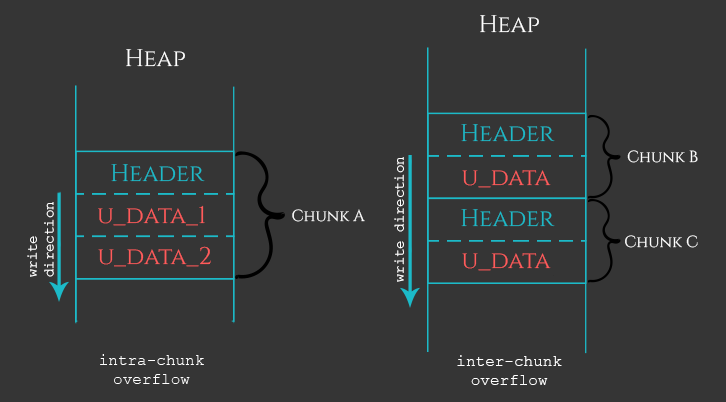
As shown in the illustration above, the intra-chunk heap overflow happens when the user has the ability to supply more data to u_data_1 and cross the boundary between u_data_1 and u_data_2. In this way the fields/properties of the current object get corrupted. If the user supplies more data than the current Heap chunk can accommodate, then the overflow becomes inter-chunk and results into a corruption of the adjacent chunk(s).
Intra-chunk Heap overflow
To illustrate how an intra-chunk Heap overflow looks like in practice we can use the following example and compile it with “-O” (optimization flag) to have a smaller (binary) program (easier to look through).
/*azeria@labs:~/exp $ gcc intra_chunk.c -o intra_chunk -O*/
#include "stdlib.h"
#include "stdio.h"
struct u_data //object model: 8 bytes for name, 4 bytes for number
{
char name[8];
int number;
};
int main ( int argc, char* argv[] )
{
struct u_data* objA = malloc(sizeof(struct u_data)); //create object in Heap
objA->number = 1234; //set the number of our object to a static value
gets(objA->name); //set name of our object according to user's input
if(objA->number == 1234) //check if static value is intact
{
puts("Memory valid");
}
else //proceed here in case the static value gets corrupted
{
puts("Memory corrupted");
}
}
The program above does the following:
- Defines a data structure (u_data) with two fields
- Creates an object (in the Heap memory region) of type u_data
- Assigns a static value to the number’s field of the object
- Prompts user to supply a value for the name’s field of the object
- Prints a string depending on the value of the number’s field
So in this case we also suspect that the corruption might happen after the function “gets”. We disassemble the target program’s main function to get the address for a break-point.
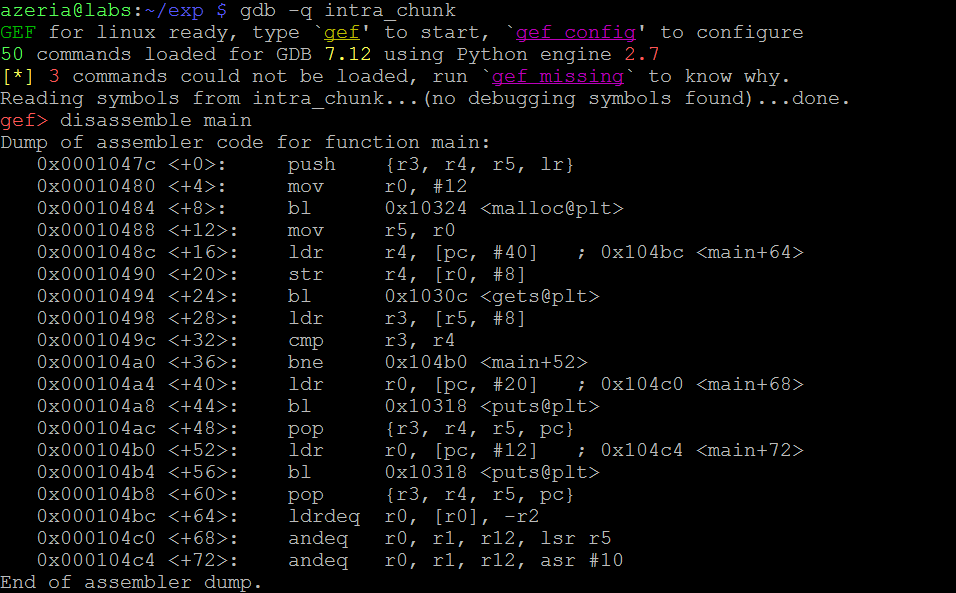
In this case we set the break-point at address 0x00010498 – right after the function “gets” is completed. We configure GEF to show us the code only. We then run the program and provide 7 A’s as a user input.
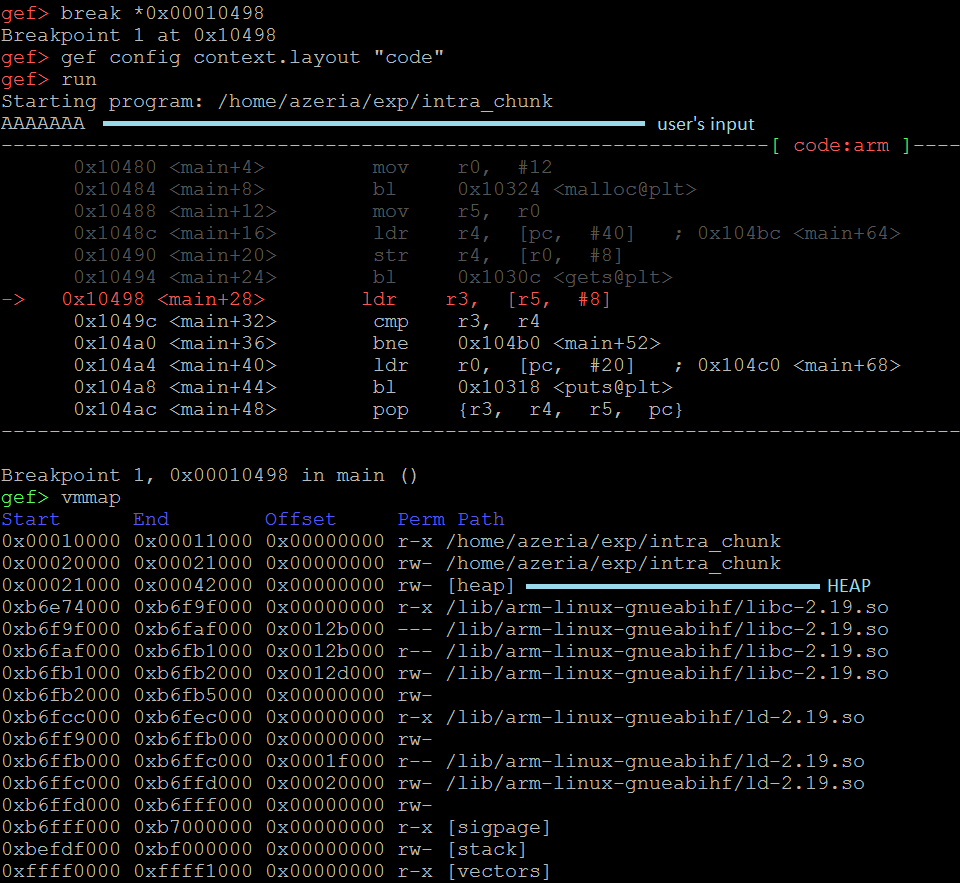
Once the break-point is hit, we quickly lookup the memory layout of our program to find where our Heap is. We use vmmap command and see that our Heap starts at the address 0x00021000. Given the fact that our object (objA) is the first and the only one created by the program, we start analyzing the Heap right from the beginning.
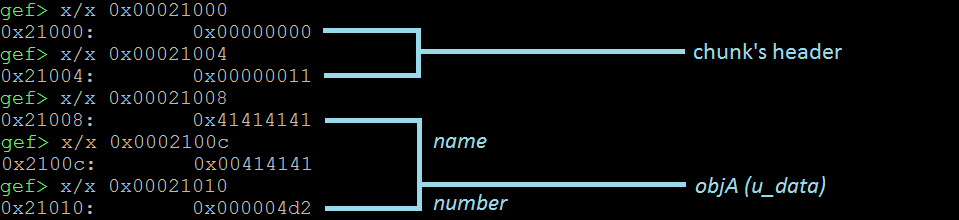
The picture above shows us a detailed break down of the Heap’s chunk associated with our object. The chunk has a header (8 bytes) and the user’s data section (12 bytes) storing our object. We see that the name field properly stores the supplied string of 7 A’s, terminated by a null-byte. The number field, stores 0x4d2 (1234 in decimal). So far so good. Let’s repeat these steps, but in this case enter 8 A’s.
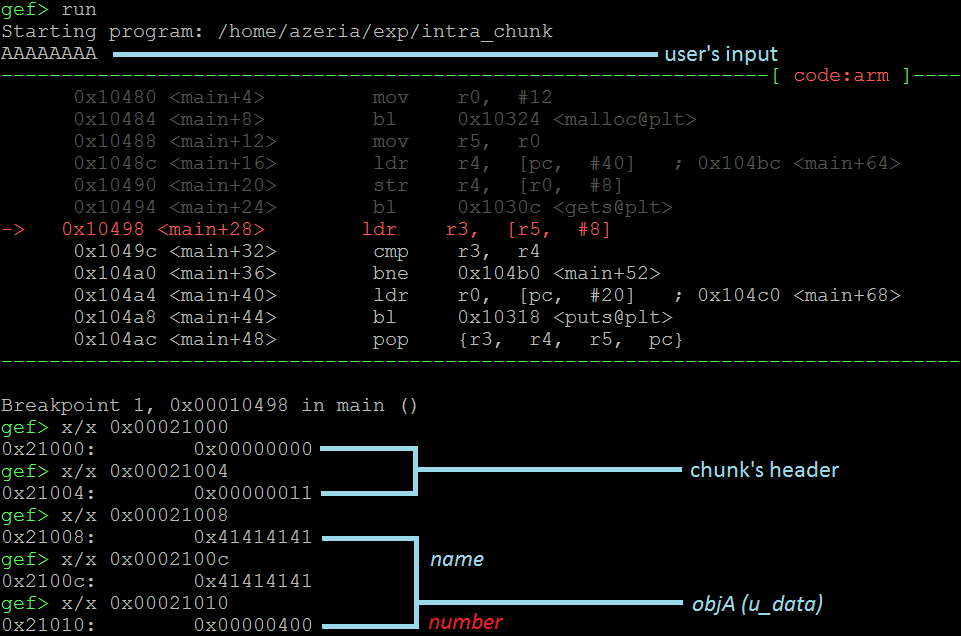
While examining the Heap this time we see that the number’s field got corrupted (it’s now equal to 0x400 instead of 0x4d2). The null-byte terminator overwrote a portion (last byte) of the number’s field. This results in an intra-chunk Heap memory corruption. Effects of such a corruption in this case are not devastating, but visible. Logically, the else statement in the code should never be reached as the number’s field is intended to be static. However, the memory corruption we just observed makes it possible to reach that part of the code. This can be easily confirmed by the example below.

Inter-chunk Heap overflow
To illustrate how an inter-chunk Heap overflow looks like in practice we can use the following example, which we now compile without optimization flag.
/*azeria@labs:~/exp $ gcc inter_chunk.c -o inter_chunk*/
#include "stdlib.h"
#include "stdio.h"
int main ( int argc, char* argv[] )
{
char *some_string = malloc(8); //create some_string "object" in Heap
int *some_number = malloc(4); //create some_number "object" in Heap
*some_number = 1234; //assign some_number a static value
gets(some_string); //ask user for input for some_string
if(*some_number == 1234) //check if static value (of some_number) is in tact
{
puts("Memory valid");
}
else //proceed here in case the static some_number gets corrupted
{
puts("Memory corrupted");
}
}
The process here is similar to the previous ones: set a break-point after function “gets”, run the program, supply 7 A’s, investigate Heap.
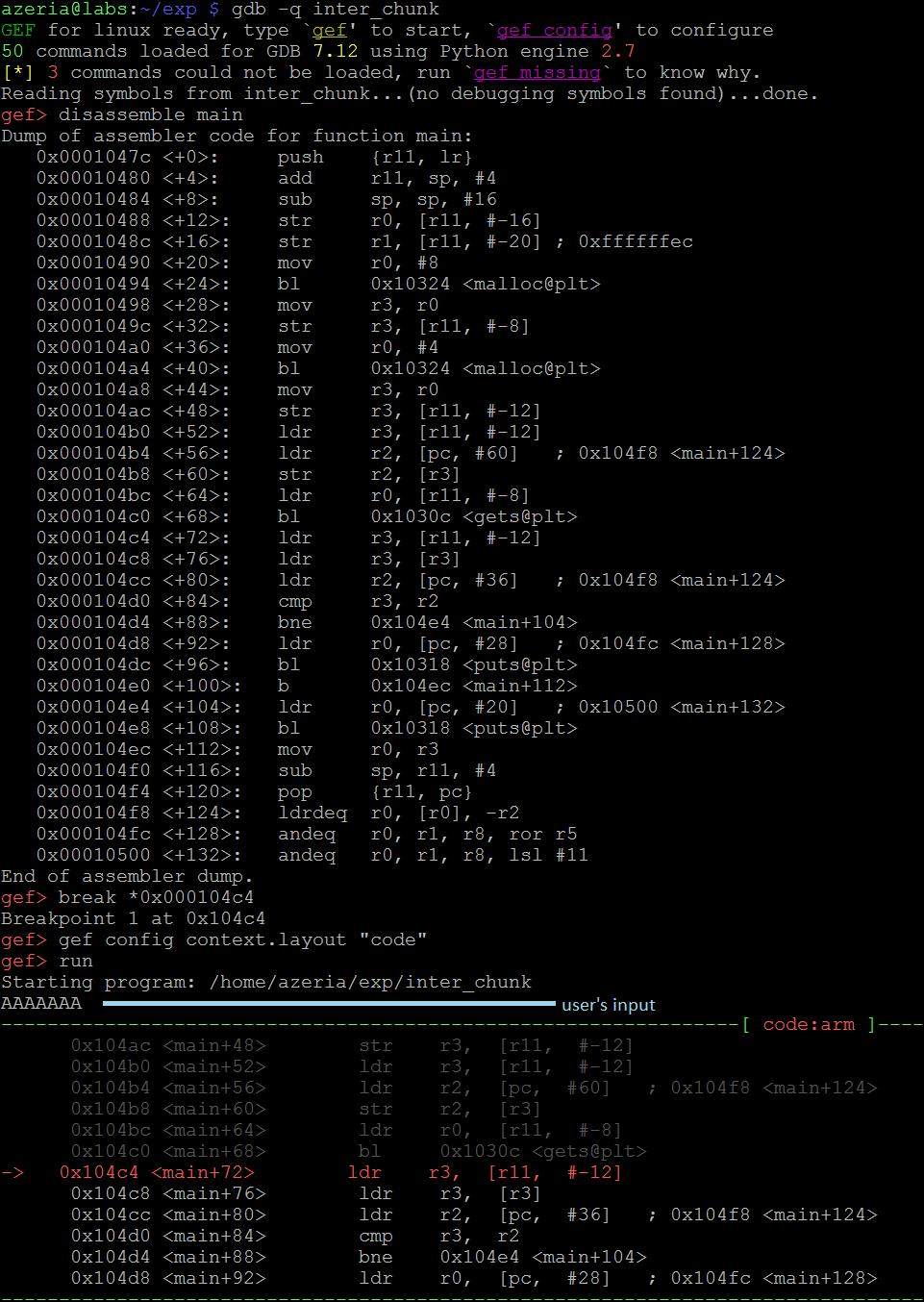
Once the break-point is hit, we examine the Heap. In this case, we have two chunks. We see (image below) that their structure is in tact: the some_string is within its boundaries, the some_number is equal to 0x4d2.
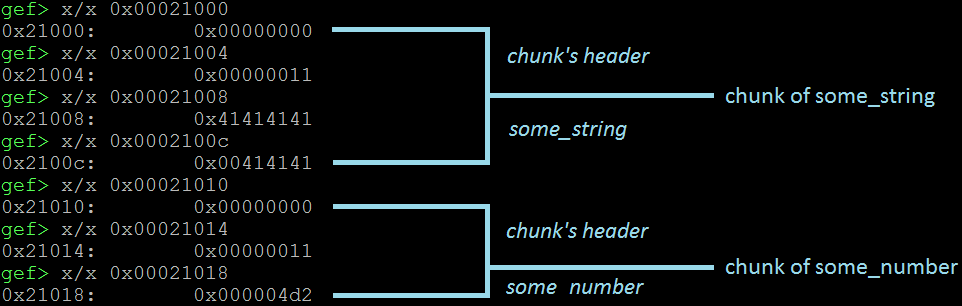
Now, let’s supply 16 A’s and see what happens.
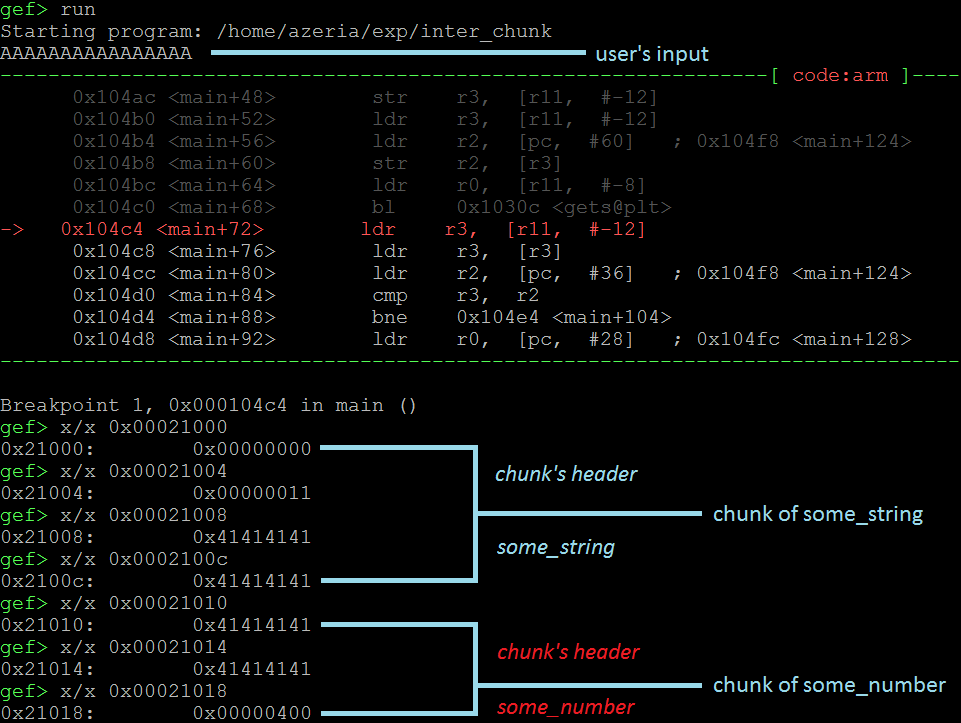
As you might have guessed, providing too much of input causes the overflow resulting into corruption of the adjacent chunk. In this case we see that our user input corrupted the header and the first byte of the some_number’s field. Here again, by corrupting the some_number we manage to reach the code section which logically should never be reached.